Method
In this work, we control the motion in generated videos by specifying bounding boxes and their associated trajectories. Our framework is built on Stable Video Diffusion, a publicly available image-to-video diffusion model.
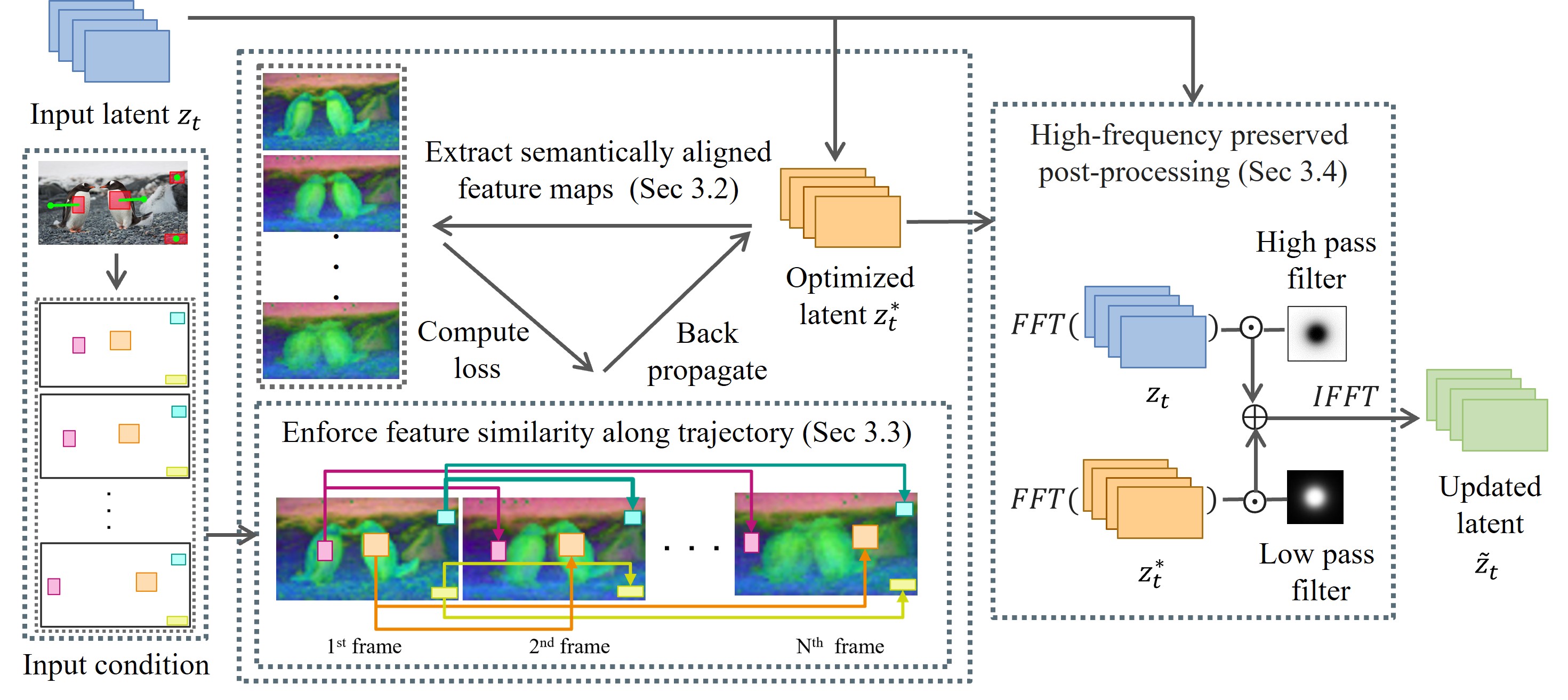
To control trajectories of scene elements during the denoising process, we optimize latent $z_t$ at specific timesteps $t$ as follows:
(1) We extract semantically aligned feature maps from the denoising U-Net, where regions belonging to the same objects across frames have similar feature vectors.
(2) We optimize the latent $z_t^*$ with a loss that encourages cross-frame feature similarity along the input trajectory.
(3) To preserve the visual quality of the generated video, a frequency-based post-processing method is applied to retain high-frequency noise of the original latent $z_t$. The updated latent $\tilde{z}_t$ is input to the next denoising step.